Bí quyết để Vibe Code AI Agent cho riêng bạn
Tool descriptions, router pattern, và “tuning surfaces” — cách debug agent trong vài phút thay vì vài giờ

Mở đầu: Khoảnh khắc tôi biết mọi thứ đã thay đổi
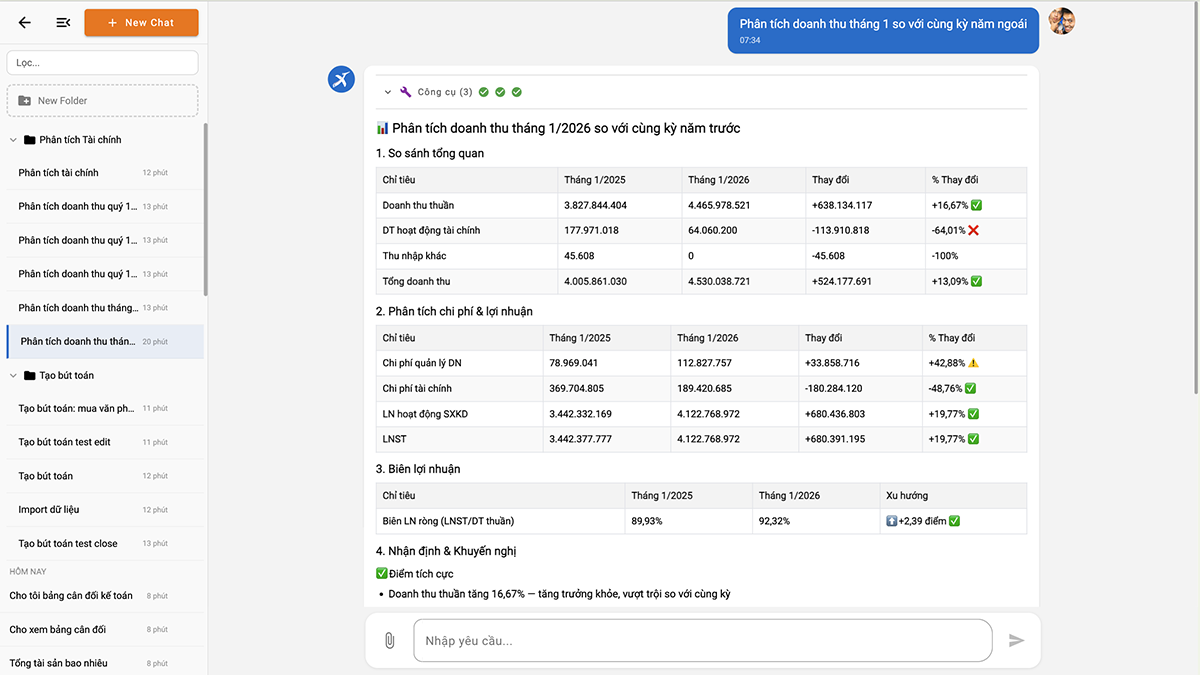
Tôi gõ vào phần mềm kế toán của mình: “Phân tích doanh thu tháng 1/2026 so với cùng kỳ năm trước.”
Ba công cụ. Không có dòng code nào tôi lập trình cứng cho quy trình này.
Đầu tiên, agent tự gọi báo cáo kết quả kinh doanh tháng 1/2026. Rồi tự gọi tiếp báo cáo tháng 1/2025. Và bước thứ ba là bước khiến tôi sững lại: agent tự viết một đoạn code để tính tăng trưởng, biên lợi nhuận, và so sánh từng chỉ tiêu. Rồi trả lời: “Doanh thu thuần tăng 17%, lợi nhuận ròng tăng 20%, biên lợi nhuận cải thiện từ 90% lên 92%. Tuy nhiên chi phí quản lý tăng 43%, nhanh hơn tốc độ tăng doanh thu. Khuyến nghị: rà soát chi phí quản lý.”
Không phải template. Không phải báo cáo có sẵn. Agent đọc dữ liệu thật, viết code phân tích thật, và đưa ra nhận định mà một kế toán trưởng sẽ đưa ra. Ba công cụ, hoàn toàn tự động.
Đó là Vietbooks Agentic, phiên bản AI sắp ra mắt của phần mềm kế toán mà tôi xây dựng từ 2017 cho thị trường Việt Nam. Và đó cũng là khoảnh khắc khẳng định rõ sự khác biệt giữa chatbot và agent trong tư duy của tôi. Chatbot trả lời câu hỏi. Agent giải quyết vấn đề.
Jensen Huang tại GTC 2026: “Mọi công ty trên thế giới đều cần một chiến lược agentic AI. Đây là máy tính mới” [1]. Nhưng hiểu agent và xây agent là hai chuyện khác nhau. Theo Gartner (tháng 4/2026), 57% lãnh đạo IT thừa nhận dự án AI thất bại vì “kỳ vọng quá nhiều, quá nhanh.” Cùng khảo sát cũng chỉ ra: hiệu quả đầu tư (ROI) từ AI không đến từ model tinh vi hơn, mà từ cách công nghệ được tích hợp và gắn với nhu cầu vận hành thực tế [2].
Điều quan trọng nhất trong năm nay có lẽ là việc hiểu rõ agent hoạt động ra sao và tự tay xây dựng agent cho riêng mình. Khi bạn hiểu cơ chế bên trong, bạn biết cách tích hợp agent vào đúng quy trình vận hành của mình, thay vì kỳ vọng một “hộp đen” tự giải quyết mọi thứ. Hiểu là điều kiện tiên quyết để đạt hiệu quả đầu tư cao nhất cho bản thân và doanh nghiệp của bạn.
Trong quá trình này, tôi đã nghiệm ra một kỹ thuật phát triển agent cực kỳ hiệu quả tôi gọi là tuning surfaces. Kỹ thuật này giúp tôi xây 46 tools và 5 agents trong 3 ngày, với 303 bài test đạt 100% pass rate. Bài viết này chia sẻ toàn bộ hành trình đó. Chỉ cần biết vibe code. Nếu bạn chưa biết, hãy đọc bài trước của tôi trước.
Phần 1: Agent là gì? — Chỉ 3 thành phần
Bỏ qua mọi mỹ từ marketing, agent chỉ có 3 thứ trọng yếu:
🧠 Bộ não (LLM) là engine suy luận quyết định “làm gì tiếp theo.” Giống một nhân viên thông minh: đọc yêu cầu, nghĩ xem cần thông tin gì, rồi hành động.
🤲 Đôi tay (Tools) là các hàm mà LLM có thể gọi: tra cứu database, tìm kiếm web, gọi API, tạo báo cáo… Đây là sự khác biệt cốt lõi: chat chỉ trả lời, agent hành động.
🔄 Vòng lặp (Loop) là cơ chế giúp agent không chỉ gọi một tool rồi dừng. Nó lặp: nghĩ → hành động → quan sát kết quả → nghĩ tiếp → hành động tiếp… cho đến khi đủ thông tin để trả lời.
Agent = LLM (bộ não) + Tools (đôi tay) + Loop (vòng lặp)Ví dụ cụ thể: user hỏi “So sánh doanh thu quý 1 năm nay với năm ngoái.” Agent nghĩ: “Cần doanh thu Q1 năm nay trước” → gọi get_revenue(Q1-2026) → nhận 500 triệu → nghĩ: “Giờ cần Q1 năm ngoái” → gọi get_revenue(Q1-2025) → nhận 420 triệu → nghĩ: “Đủ rồi, tổng hợp” → trả lời user.
Nghe đơn giản? Đúng vậy, về lý thuyết. Nhưng “con quỷ (devil) nằm trong chi tiết.” Hãy cùng đi qua hành trình xây Vietbooks Agentic, nơi tôi gặp đủ loại quỷ và tìm cách trị từng con.
💡 Không phải model nào cũng làm agent được. Model cần hỗ trợ function calling (tool calling). Ở đây tôi dùng GLM 5.1: mã nguồn mở, hiệu suất gần Opus với 1/8 chi phí, và đạt độ chính xác cao khi call tool. Danh sách đầy đủ các model khuyên dùng ở Phụ lục A.
Phần 2: Hành trình xây Vietbooks Agentic — Câu chuyện = Bài học
Vietbooks là phần mềm kế toán tôi xây dựng từ 2017 cho thị trường Việt Nam. Trước đây nó chỉ là công cụ ghi nhận và lên báo cáo thuần. Năm nay, tôi biến nó thành agentic: AI không chỉ trả lời mà còn hành động, tra cứu luật kế toán, tạo bút toán, phân tích tài chính, xử lý hóa đơn, hoàn toàn tự động.
Toàn bộ phần này tôi có lên kế hoạch từ lâu (cuối năm 2025), và mới đây đã xây dựng bằng vibe code với Claude Code, trong khoảng 3 ngày. Nghe khó tin? Trong kỷ nguyên AI coding, đây là tốc độ thật, nếu bạn hiểu đúng cách agent hoạt động.
🔧 Bước 1: Tool đầu tiên, và phát hiện bất ngờ
Tool đầu tiên tôi xây là get_account_rules, tra cứu quy tắc hạch toán cho một tài khoản. Ý tưởng đơn giản: user hỏi “TK 331 hạch toán thế nào?”, agent gọi tool, trả kết quả.
Mỗi tool chỉ cần 3 thứ: tên, mô tả, và danh sách tham số (chi tiết kỹ thuật ở Phụ lục B). Tôi viết mô tả đầu tiên khá qua loa: “Lấy quy tắc tài khoản kế toán.” Agent gọi đúng tool. Tuyệt vời.
Rồi tôi thêm tool thứ hai: search_regulation_knowledge, tìm kiếm quy định kế toán chung. Và mọi thứ bắt đầu hỗn loạn. Khi user hỏi “Phải trả người bán hạch toán thế nào?”, agent gọi… tool tìm kiếm chung thay vì tool tra cứu tài khoản. Sai tool, sai kết quả.
Tôi đổ lỗi cho LLM. Tôi thử model khác. Vẫn sai.
Sau một lúc debug, tôi phát hiện vấn đề: mô tả tool quá mơ hồ. LLM không biết phân biệt khi nào dùng tool nào. Tôi viết lại mô tả cho get_account_rules: thêm “Dùng khi user hỏi về cách hạch toán, Bên Nợ/Có, hoặc phương pháp kế toán của một tài khoản cụ thể.”
Lập tức agent chọn đúng tool.
Bài học đắt giá nhất: 80% lỗi agent đến từ tool description, không phải LLM kém. Tool description chính là “bản mô tả công việc” cho nhân viên AI. Viết mơ hồ thì nhân viên làm sai, không phải vì họ thiếu năng lực, mà vì bạn giao việc không rõ ràng.
💡 Thêm “Dùng khi user hỏi về…” vào mô tả tool giúp LLM chọn đúng gần như 100%. Kỹ thuật “explicit tool-to-question mapping” đơn giản nhưng cực kỳ hiệu quả. Áp dụng cho mọi loại agent, không chỉ kế toán.
🔄 Bước 2: Vòng lặp đầu tiên — “Agent nói mãi không xong”
Khi đã có 5 tools, tôi xây vòng lặp agent. Logic cốt lõi chỉ ~30 dòng code (xem Phụ lục C). Ý tưởng đơn giản: gọi LLM, nếu nó muốn gọi tool thì gọi, đưa kết quả trở lại, lặp lại cho đến khi nó trả lời text.
Chạy thử: agent gọi tool, nhận kết quả, gọi tool tiếp… rồi gọi tiếp… rồi gọi tiếp… hết 10 vòng mà chưa trả lời. Agent cứ nghĩ cần thêm thông tin. Nó không biết khi nào là “đủ.”
Giải pháp gồm hai phần. Thứ nhất, khi còn 3 vòng trở xuống, thêm một vào system prompt để nhắc agent: “⚠️ Còn 3 lượt. Hãy trả lời sớm nếu đã đủ dữ liệu.” Khi là vòng cuối: “Đây là lượt cuối, PHẢI trả lời ngay, KHÔNG gọi thêm tool.” Thứ hai, ở vòng cuối cùng, buộc agent trả lời text bằng cách set:
tool_choice: isLastRound ? "none" : "auto"Phần nhắc nhở giúp agent tự biết “ngân sách” còn bao nhiêu và chủ động tổng hợp câu trả lời sớm. Phần tool_choice: "none" là chốt chặn cuối cùng, đảm bảo agent không thể gọi thêm tool dù muốn.
💡 Luôn set max rounds (10 là mặc định tốt) và force answer ở round cuối. Hai thiết lập này ngăn agent đốt tiền vô tận. Trong suốt 303 bài test của Vietbooks, chưa bao giờ agent cần quá 6 rounds.
📋 Bước 3: System prompt — “Nói ĐỪNG mà nó vẫn làm”
System prompt là nơi bạn dạy agent “luật chơi”: nó là ai, biết làm gì, khi nào dùng tool nào, trả lời thế nào.
Tôi viết: “Không xử lý hóa đơn điện tử trong phần chat.” Vì phần này tôi đã có quy trình xử lý tự động tối ưu. Yêu cầu vậy là quá rõ ràng, đúng không?
Thế nhưng agent vẫn cố xử lý hóa đơn. Tôi viết mạnh hơn: “KHÔNG nên xử lý hóa đơn.” Nó vẫn tiếp tục vi phạm.
Cuối cùng, tôi viết: “DỪNG NGAY. KHÔNG gọi bất kỳ tool nào. Trả lời: ‘Vui lòng sử dụng chức năng nhập hóa đơn.’” Agent tuân thủ 100%.
Bài học: LLM xử lý chỉ dẫn tích cực mạnh hơn nhiều so với phủ định. “Đừng làm X” yếu hơn “Làm Y thay vì X.” Đây là đặc điểm của mọi LLM, không riêng model nào.
💡 System prompt hiệu quả chỉ cần 3 phần: context (ngày, thông tin công ty), quy tắc chọn tool (explicit mapping “Khi hỏi X → dùng Y”), và định dạng câu trả lời. Toàn bộ 5 agents của Vietbooks chỉ dùng 11.300 ký tự system prompt, ngắn hơn bài viết này. Viết system prompt nên trực tiếp, rõ ràng. Nên nhớ system prompt được gửi kèm mọi message: prompt dài = tốn token = tốn tiền.
🚦 Bước 4: Một agent không đủ — Router pattern
Khi số tools tăng lên 46 để hỗ trợ đầy đủ các chức năng, một agent duy nhất bắt đầu “choáng ngợp”: system prompt dài, chọn sai tool vì quá nhiều lựa chọn, và mỗi request tốn thêm nhiều token.
Giải pháp: tôi tách agent này thành nhiều agent chuyên biệt, điều phối bởi một RouterAgent, giống tổng đài viên phân loại cuộc gọi rồi chuyển đến đúng bộ phận. Đây cũng là kỹ thuật tôi rất thích và học được khi dùng Claude Code: agent chính dùng nhiều sub-agents để phân tích code song song, vừa nhanh vừa hiệu quả.
RouterAgent của tôi phân loại mỗi tin nhắn và quyết định: tự trả lời hay chuyển cho sub-agent chuyên biệt.
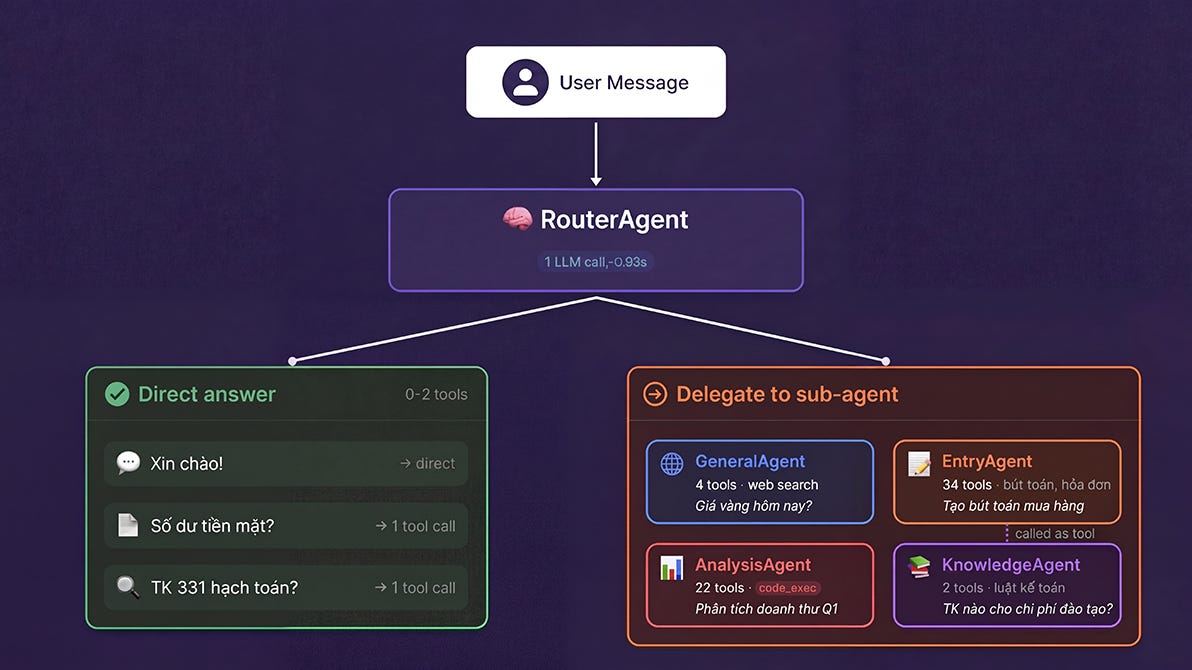
Điểm quan trọng: RouterAgent không chỉ phân loại rồi chuyển tiếp. Với câu hỏi đơn giản (chat, tra cứu 1 báo cáo, hỏi số dư), RouterAgent tự trả lời chỉ với 1-2 tool calls, không cần chạy sub-agent. Chỉ khi cần xử lý phức tạp (tìm kiếm web, tạo bút toán, phân tích sâu) mới chuyển cho sub-agent. Điều này giúp phản hồi nhanh hơn và tiết kiệm token cho các câu hỏi thường gặp.
Hơn nữa, mỗi sub-agent chỉ giải quyết vấn đề chuyên môn của mình (loại prompt riêng), và thấy tools của riêng mình. Không agent nào bị “phân tâm” bởi tools của agent khác.
AnalysisAgent thấy 22 tools bao gồm 17 tool kế toán, web search, và đặc biệt là
code_exec(tool cho phép agent tự viết code phân tích, chính là bước thứ ba ở đầu bài).EntryAgent thấy 33 tools cho tạo bút toán, xử lý hóa đơn, quản lý đối tượng và 1 tool để dùng KnowledgeAgent. Đây cũng là pattern đơn giản mà hiệu quả tôi phát hiện: sub-agent có thể chỉ là một tool nội bộ. Không cần framework, không cần message bus. Agent chính gọi sub-agent giống gọi một hàm bình thường: truyền câu hỏi vào, nhận text ra.
💡 Router call chỉ tốn ~300 token và ~0.3 giây, rẻ hơn nhiều so với gửi 46 tool descriptions trong mỗi request. Khi agent có hơn 10 tools, hãy nghĩ đến Router.
🎯 Bước 5: Tuning Surfaces — Kỹ thuật then chốt để vibe code agent thành công
Đây là kỹ thuật quan trọng nhất trong toàn bộ bài viết, và tôi chưa thấy ai chia sẻ cách tiếp cận này.
Xây agent không giống xây phần mềm thông thường. Với code truyền thống, test fail thì bạn biết chính xác dòng code nào sai. Với agent, bạn viết system prompt, đưa tools, và model tự quyết định làm gì. Câu hỏi không phải “hàm này có chạy đúng không?” (đó là code thuần, test bình thường). Câu hỏi là: “Khi user nói ‘chi 5 triệu mua văn phòng phẩm’, model có chọn đúng tool(s) với đúng tham số không?”
Khi mới test agent, mỗi lần test fail tôi lại đoán: “Model kém? Prompt chưa rõ? Tool description sai?” Rồi thử sửa hết chỗ này đến chỗ khác. Mất hàng giờ và quan trọng hơn là rất khó để tự động hóa hoàn toàn để “vibe code”.
Sau nhiều lần, tôi đúc kết cho mình một kỹ thuật riêng (và đây cũng là một khái niệm đã có từ ML evaluation): tuning surfaces. Ý tưởng: test phải được thiết kế sao cho mỗi test failure phải map đến đúng MỘT “surface”, một nơi cụ thể để sửa. Không đoán mò. Mỗi test mang theo hai thông tin: tuningSurface (sửa CÁI GÌ) và fixHint (sửa NHƯ THẾ NÀO).
Test fail → check tuningSurface → biết sửa CÁI GÌ
→ check fixHint → biết sửa NHƯ THẾ NÀO
→ sửa → chạy lại → verifyTôi hệ thống hóa thành 5 surfaces chính (bảng đầy đủ ở Phụ lục D):
Agent gọi sai tool? →
PROMPT_TOOL_SELECTION: thêm mapping “Khi hỏi X → dùng Y” vào system promptAgent gọi đúng tool nhưng sai thứ tự? →
PROMPT_WORKFLOW: đánh số bước trong promptAgent không hiểu tool làm gì? →
TOOL_DESCRIPTION: viết lại mô tả toolAgent truyền sai tham số? →
TOOL_PARAMS: thêm ví dụ vào parameter descriptionAgent trả lời đúng nhưng sai format? →
PROMPT_ANSWER_FORMAT: thêm template trả lời
Ví dụ thực tế: 0 → 100% trong 3 lần chạy
Khi tôi thêm một nhóm tools mới để mở canvas và trình bày artifact (báo cáo tài chính, bút toán nháp), toàn bộ 16 test mới fail. Agent trả lời bằng text thay vì gọi tool. Nếu không có tuning surfaces, tôi sẽ ngồi đoán: prompt sai? Model kém? Tool description chưa rõ?
Nhưng triệu chứng “agent không gọi tool” chỉ tôi kiểm tra hai chỗ theo thứ tự: đầu tiên là mảng tools[] gửi cho LLM, sau đó là system prompt. Hóa ra tôi quên đăng ký nhóm tools mới vào mảng tools[]. LLM không thấy tools thì đương nhiên không gọi. Sửa một dòng import, chạy lại: 10/16 pass.
6 test còn lại fail vì triệu chứng tương tự nhưng nguyên nhân khác: system prompt thiếu trigger keywords. User nói “tải về file Excel” nhưng agent hiểu đó là câu hỏi chung, không phải yêu cầu hành động. Thêm mapping cụ thể vào system prompt: "xuất dữ liệu", "export", "tải về Excel" → dùng request_data_export. Chạy lại: 16/16. Ba lần chạy, mỗi lần biết chính xác sửa ở đâu.
Trong quá trình phát triển Vietbooks Agentic, tôi chạy 20 lần tuning iterations trên tất cả agents, mỗi lần tôi đều biết chính xác sửa ở đâu. Không một lần đoán mò.
💡 Nếu bạn quên tất cả mọi thứ trong bài này, hãy chỉ nhớ một điều: Tuning Surfaces biến bạn từ người “cầu nguyện cho AI chạy đúng” thành người biết chính xác sửa ở đâu. Ở Phần 3, tôi chia sẻ prompt thực tế để bạn vibe code agent với kỹ thuật này.
🧪 Bước 6: Test — “Đo được thì cải thiện được”
Tôi xây kim tự tháp test 3 tầng cho agent (chi tiết ở Phụ lục E):
Tầng 1, Unit test: Test logic thuần, không cần LLM. $0, chạy trong 0.25 giây.
Tầng 2, Tool selection: Chỉ kiểm tra LLM có gọi đúng tool không. ~$0.01/test. Bắt được 80% lỗi với 5% chi phí.
Tầng 3, Full E2E: Chạy toàn bộ agent loop, kiểm tra kết quả cuối. ~$0.05-0.10/test.
Kết quả: 303 bài LLM test + 709 unit test, 100% pass rate, tổng chi phí test: $12.47, ít hơn một ly cà phê.
💡 Đừng chạy tất cả test cùng lúc (20+ phút tổng cộng). Chạy Tầng 2 trước (~3 phút), sửa, rồi mới chạy Tầng 3. Sửa giữa các batch, không phải sau khi tất cả đã fail.
Phần 3: Bắt đầu xây agent của bạn
Bạn không cần 46 tools và 5 agents để bắt đầu. Vietbooks Agentic bắt đầu từ đúng 1 tool và 1 vòng lặp. Và nhớ: bạn đang vibe code, không cần tự gõ từng dòng. Hãy copy code ở Phụ lục C vào Cursor/Claude Code và bảo AI: “Hãy dựa trên cấu trúc vòng lặp này, tạo cho tôi một agent thực hiện [tác vụ của bạn].” Nhờ tuning surfaces, AI sẽ tự debug lỗi cho bạn. Với GLM 5.1 hoặc Gemma 4, chi phí thử nghiệm gần như bằng 0.
Đây là các bước cụ thể:
⚙️ Setup: Tạo tài khoản OpenRouter (một API, hàng chục model). Chọn model hỗ trợ tool calling: GLM 5.1 cho chi phí thấp với chất lượng cao, hoặc Gemma 4 nếu muốn rẻ nhất. Backend: Node.js hoặc Python.
🔧 Tool đầu tiên: Chọn một tác vụ đơn giản bạn muốn agent làm: tra cứu sản phẩm, query database, tìm kiếm web. Viết mô tả tool rõ ràng với “Dùng khi user hỏi về…”
🔄 Agent loop: Tôi đã cung cấp đoạn code cốt lõi (vòng lặp 30 dòng) ở Phụ lục C. Nó là tất cả những gì bạn cần. Hãy copy nó vào dự án của bạn, thay
executeToolCallbằng hàm xử lý tool của bạn. Nhớ set max rounds và force answer ở round cuối.📋 System prompt: 3 phần: context, quy tắc chọn tool, format trả lời. Ngắn gọn, cụ thể, rõ ràng.
🧪 Test + Tuning Surfaces: Prompt cho AI: “Hãy thiết kế test cho mỗi tool. Mỗi test phải có tuningSurface và fixHint rõ ràng. Chạy test và sửa cho đến khi tất cả pass.” Nhờ tuning surfaces, AI sẽ tự biết sửa ở đâu khi test fail.
Khi nó hoạt động, và nó sẽ hoạt động, bạn sẽ trải nghiệm đúng khoảnh khắc mà tôi mô tả ở đầu bài.
💡 Đừng bắt đầu với framework (LangChain, CrewAI, AutoGen). Nên dùng LLM API call thẳng + vòng lặp for là đủ. Khi hiểu agent hoạt động thế nào rồi, bạn chuyển sang framework nếu muốn. Nên hiểu cách agent vận hành cơ bản trước.
🔒 Bảo mật
Các cảnh báo an toàn ở bài Vibe Code vẫn áp dụng, cộng thêm:
Giới hạn max rounds và token budget: Agent không có giới hạn sẽ gọi tool mãi mãi, đốt tiền API của bạn.
Cẩn thận với tools có tác động lớn: Không nên cho agent tool xóa dữ liệu hoặc thực hiện giao dịch không thể hoàn tác (undo). Trong Vietbooks, agent chỉ tạo bản nháp, người dùng phải phê duyệt trước khi ghi sổ.
Loại bỏ trường nhạy cảm ở tầng database: Khi tool query database, dùng projection để loại trường password, API token, v.v. Agent không bao giờ nhìn thấy dữ liệu nhạy cảm.
Kết luận: Personalized Agent, siêu năng lực mới
Context, Tool Management đề cập bên trên là 2 trong 4 kỹ thuật quan trọng để phát triển và vận hành agent, gọi chung là Harness Engineering (cách “cầm cương” AI agent). Bài viết tiếp theo tôi sẽ đi vào 2 trụ cột còn lại: Memory và Sandbox.
Sau khi hiểu cách agent hoạt động, cộng với kỹ thuật Tuning Surfaces, nếu bạn biết vibe code, bạn sẽ có thể vibe code agent. Agent hiểu nghiệp vụ của bạn, nói ngôn ngữ của bạn, làm việc 24/7. Đó là siêu năng lực mới trong kỷ nguyên AI.
Bạn đang xây agent cho lĩnh vực gì? Gặp vấn đề gì? Chia sẻ ở phần bình luận nhé!
Nếu bạn chưa biết vibe code, hãy đọc bài hướng dẫn vibe code để bắt đầu. Nếu muốn hiểu sâu về RAG, một loại tool quan trọng cho agent, hãy đọc bài về cách tôi xây agent tra cứu luật kế toán.
Tài liệu tham khảo
[1] Jensen Huang. NVIDIA GTC 2026 Keynote. March 2026.
https://www.nvidia.com/gtc/keynote/
[2] Gartner. “Gartner Says AI Projects in I&O Stall Ahead of Meaningful ROI Returns.” April 7, 2026.
Phụ lục
A. Các model khuyên dùng cho agent (tháng 4/2026)
Chất lượng cao (closed-source):
Claude Sonnet 4.6 — cân bằng tốt giữa chất lượng và chi phí
GPT-5.4 — native computer use, 1M context
Gemini 3.1 Pro — reasoning mạnh, 1M context, output dài (65K tokens)
Claude Opus 4.6 — tốt nhất cho tác vụ phức tạp (nhưng đắt)
Mã nguồn mở:
GLM 5.1 — #1 SWE-Bench Pro, hiệu suất gần Opus với 1/8 chi phí. MIT license. Đây là model tôi dùng cho Vietbooks Agentic.
Qwen 3.6 Plus — multimodal (vision + text), hiệu suất gần GLM 5.1. Tốt cho agent cần xử lý hình ảnh.
Gemma 4 — rẻ nhất, Apache 2.0 license. Phù hợp để bắt đầu và fine-tune sau.
Truy cập: OpenRouter cho phép dùng tất cả model trên qua một API duy nhất.
B. Cấu trúc Tool — Chi tiết kỹ thuật
Mỗi tool là một object JSON theo chuẩn function calling. Ví dụ thực tế từ Vietbooks:
{
name: "get_account_balance",
description: "Lấy số dư tài khoản theo mã tài khoản hoặc đầu mã "
+ "(VD: '111' cho tiền mặt, '131' cho phải thu khách hàng). "
+ "Trả về tổng nợ, tổng có và số dư.",
parameters: {
type: "object",
properties: {
account_prefix: {
type: "string",
description: "Mã tài khoản hoặc đầu mã (VD: '111', '131', '331')"
},
start_date: {
type: "string",
description: "Ngày bắt đầu (YYYY-MM-DD), bỏ qua để lấy từ đầu"
},
end_date: {
type: "string",
description: "Ngày kết thúc (YYYY-MM-DD), bỏ qua để lấy đến hiện tại"
}
},
required: ["account_prefix"]
},
execute: async (args, context) => {
// Query MongoDB, tính tổng nợ/có/dư, trả về kết quả
}
}Quy tắc vàng khi viết tool:
Mỗi tool làm MỘT việc duy nhất
Mô tả phải nói rõ khi nào dùng tool này, kèm ví dụ cụ thể
Tham số phải có description kèm format và ví dụ (VD: “YYYY-MM-DD”)
C. Agent Loop — Code hoàn chỉnh
Đây là phiên bản đơn giản hóa từ BaseAgent thực tế của Vietbooks:
async function runAgent(userMessage: string, tools: Tool[], systemPrompt: string) {
const messages = [
{ role: "system", content: systemPrompt },
{ role: "user", content: userMessage }
];
const MAX_ROUNDS = 10;
for (let round = 0; round < MAX_ROUNDS; round++) {
const isLastRound = round === MAX_ROUNDS - 1;
const remaining = MAX_ROUNDS - round;
// Nhắc agent còn bao nhiêu lượt khi gần hết
if (round > 0 && remaining <= 3) {
messages.push({
role: "system",
content: isLastRound
? "⚠️ Đây là lượt cuối — PHẢI trả lời ngay, KHÔNG gọi thêm tool."
: `⚠️ Còn ${remaining} lượt. Hãy trả lời sớm nếu đã đủ dữ liệu.`
});
}
// Gọi LLM (force text ở round cuối)
const response = await callLLM({
model: "openrouter/glm-5.1",
messages,
tools,
tool_choice: isLastRound ? "none" : "auto"
});
// Nếu LLM trả lời text → xong
if (response.content && !response.tool_calls) {
return response.content;
}
// Nếu LLM muốn gọi tool → thực thi
if (response.tool_calls) {
messages.push(response); // Lưu lệnh gọi tool vào lịch sử
for (const toolCall of response.tool_calls) {
const result = await executeToolCall(toolCall); // Gọi hàm thật
messages.push({
role: "tool",
tool_call_id: toolCall.id,
content: JSON.stringify(result)
});
}
}
}
return "Xin lỗi, tôi không thể hoàn thành yêu cầu này.";
}Giải thích từng phần:
messages: lịch sử hội thoại, bao gồm cả tool calls và kết quảRound budget warning: khi còn ≤3 lượt, thêm tin nhắn vào system prompt nhắc agent tổng hợp câu trả lời. Giúp agent chủ động dừng sớm thay vì gọi tool đến lượt cuối
tool_choice: "auto": LLM tự quyết định gọi tool hay trả lờitool_choice: "none": chốt chặn cuối cùng, buộc LLM trả lời textexecuteToolCall: hàm thực thi tool thật (query database, gọi API, v.v.)
D. Tuning Surfaces — Bảng tra cứu đầy đủ
PROMPT_TOOL_SELECTION— Agent gọi sai tool → Thêm mapping vào system prompt. Ví dụ: “Khi hỏi TK cụ thể →get_account_rules“PROMPT_WORKFLOW— Đúng tool, sai thứ tự → Đánh số bước trong prompt. Ví dụ: “BƯỚC 1: kiểm tra corrections. BƯỚC 2: tìm template.”TOOL_DESCRIPTION— Agent không hiểu tool → Viết lại mô tả, thêm “Dùng khi…” Ví dụ: “Dùng khi user hỏi về một tài khoản cụ thể”TOOL_PARAMS— Truyền sai tham số → Thêm ví dụ vào description. Ví dụ: “account_code: ‘131’, ‘331’, ‘511’”PROMPT_ANSWER_FORMAT— Đúng nội dung, sai format → Thêm template. Ví dụ: “Trả lời gồm: Bên Nợ, Bên Có, ví dụ”
Red flags:
Tất cả test fail “no tool called” → Tool chưa nằm trong mảng
tools[]Agent trả lời quá ngắn hoặc hết max rounds → Thiếu
tool_choice: "none"ở round cuốiAgent dùng sai dữ liệu → Kiểm tra thứ tự bước trong prompt
E. Thống kê Vietbooks Agentic
Tools xây dựng: 46 (17 accounting, 5 entry, 4 template, 4 invoice, 2 search, …)
Agents: 5 (Router, Entry, Knowledge, Analysis, General)
LLM tests: 303 (71 knowledge, 94 entry, 68 analysis, 30 router, 40 E2E)
Unit tests: 709
Pass rate: 100%
Tổng chi phí test: $12.47
Tuning iterations: 20
System prompt (tổng): 11.300 ký tự
Thời gian xây dựng: ~3 ngày (vibe code với Claude Code)
Kim tự tháp test chi tiết:
Tầng 1, Unit: 709 tests, 0.25 giây, $0. Test logic thuần (phân loại tài khoản, validate, tạo mã).
Tầng 2, Tool Selection (Tier A): 1 LLM call/test, ~$0.01. Kiểm tra: đúng tool, đúng tham số. 80% lỗi bắt ở đây.
Tầng 3, Full E2E (Tier B): Multi-round, ~$0.05-0.10/test. Tool chains, workflow compliance, kết quả cuối.